
In the previous article, we discussed how to identify Roslyn analyzers that have a negative impact on the compilation time of a .NET solution. For some projects, this can represent a significant percentage of the compilation time, which can affect developer productivity and satisfaction, as well as metrics related to performance and releases.
In this next part, we’ll further explore the possibilities for optimizing the compilation of a .NET solution by focusing on the solution’s architecture and the dependencies between projects. We’ll examine a common architecture of projects within a .NET solution and attempt to apply inversion of control, a concept that is normally familiar to developers but on a different scale.
A compilation of projects that’s too often sequential
It’s very common to see a .NET solution architecture composed of several layers representing a logical division of the application. For example, a web application might consist of several layers:
- Presentation (ASP.NET Core MVC, Web API, Razor Pages, etc.)
- Application (business logic, application logic)
- Infrastructure (data access, external services, etc.)
When focusing on the relationships between these projects, we notice that they are referenced sequentially. In this example, the presentation layer has a dependency on the application layer, and the application layer has a dependency on the infrastructure layer.
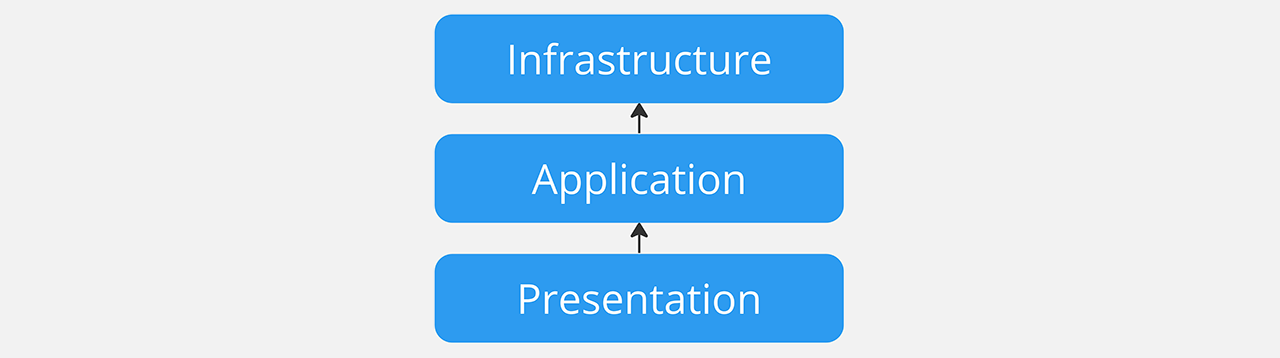
There are scenarios of sequential dependency with even more layers, where ultimately the compilation of a project depends on all other upstream projects. Another common case is when a project becomes a “god project”, containing far too much code from various unrelated concerns. This large project then becomes a nightmare for developers, who sometimes have to wait several minutes for every change.
To have a baseline for comparison, we will use this solution architecture as our starting point for compilation tests and introduce a delay in the compilation of the “Application” and “Infrastructure” projects to simulate a longer compilation time. This involves adding the following code to the projects:
<!--With this we try to simulate that a project has a lot of files to compile-->
<Target Name="SleepBeforeBuild" BeforeTargets="CoreCompile">
<Exec Command="powershell -NoLogo -NoProfile -NonInteractive -Command "Start-Sleep -Seconds 5""/>
</Target>
This will result in a 5-second delay during compilation. With this addition, the total solution compilation time is approximately 12 seconds. Let’s remember this duration as we move forward.

What is inversion of control?
Inversion of control in programming is a decoupling design pattern, which allows a component to no longer depend directly on another component.
For example, imagine a class named Worker that strongly depends on another class named Logger. The issue here is that Worker needs all the necessary information to create or access Logger, which we can call a strong coupling between the two.
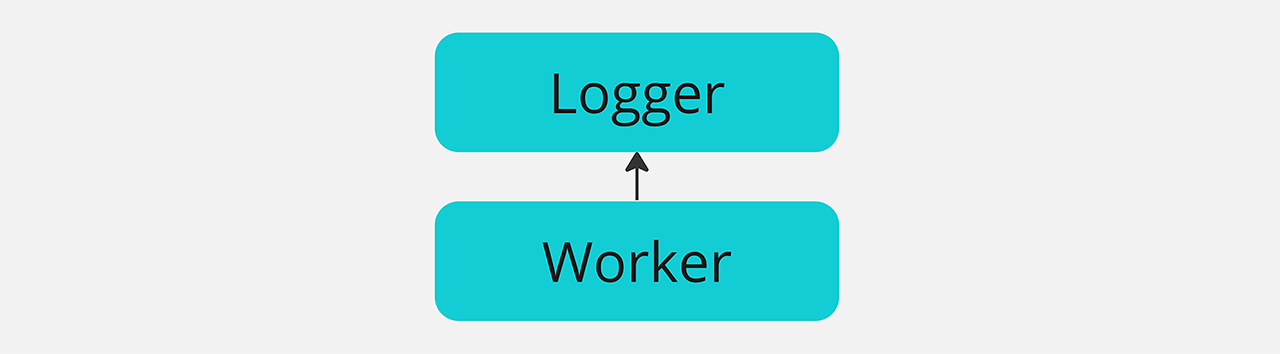
By inverting the flow of control, we can introduce an abstraction layer between components, which allows placing Worker and Logger at the same hierarchical level. Here is what the class diagram looks like after the inversion of control:

From now on, Worker no longer directly depends on Logger, but on an abstraction of Logger. This allows for the decoupling of the two components and makes Logger more easily replaceable. Worker no longer needs to know the implementation details of Logger; it just needs to know the interface of Logger.
A well-known implementation of inversion of control is dependency injection. With libraries such as Microsoft.Extensions.DependencyInjection, Autofac, and others, it is possible to list abstractions and their implementations, and the library will take care of resolving the dependencies between types.
Applying inversion of control at the solution level
Although inversion of control, or more specifically dependency injection, is a concept well known to developers, few realize that it can be applied to almost any level of software or computer system architecture. Indeed, it is possible to reverse the control flow between the modules of an application. In the case of a .NET solution, this means that we can break the strong coupling between two projects by introducing an abstraction layer between them.
The application of this concept at such a level is described in the video Clean Code: Component Coupling, Episode 17, by Robert “Uncle Bob” Martin.
Let’s revisit the example of the solution architecture we saw earlier, where the compilation lasted 12 seconds. Let’s introduce an abstraction of the infrastructure layer, so that the application layer no longer directly depends on the infrastructure layer, but rather on an abstraction of it.
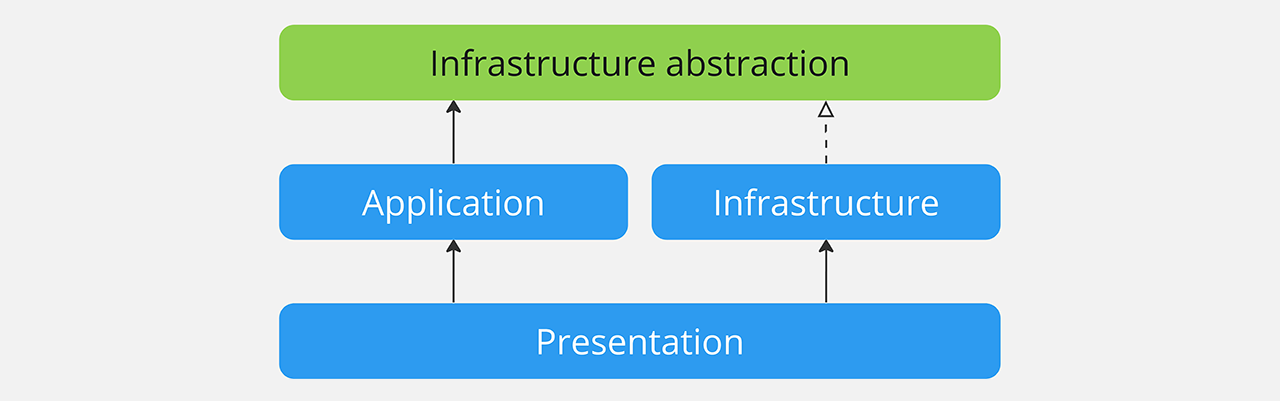
There are four advantages to introducing abstraction layers between projects:
First, there is no longer a direct coupling between the application and infrastructure layers. The compiler can now compile both the Infrastructure and Application projects simultaneously once the abstraction - which is relatively small in size - is compiled. This can reduce the total solution compilation time. In our example, the solution’s compilation time goes from 12 seconds to 7 seconds!

Second, there is an impact on the consistency of projects. In our example, the contract established between the projects is clearly defined by the abstraction, which only represents the functionalities necessary for the application layer. The boundaries are clearer, and it is now easier to maintain consistency and prevent developers from creating code that should not be found in one layer or another. Combine this with good visibility of types in each project (typically, using internal instead of public by default), and you have a more robust architecture.
Third, the direct or indirect (transitive) dependencies of a project will no longer flow into other projects. In our initial example, if the infrastructure layer referenced the Azure SDK, or a SQL database connector, these NuGet packages would end up available in the application layer. There is no need for the application layer to have access to them, and an inattentive developer could mistakenly use them in the wrong place. Introducing an abstraction layer prevents these dependencies from ending up in unrelated projects.
Fourth, and in rare cases, there is a possibility to replace one implementation with another. In a way, Microsoft is increasingly creating libraries with abstractions whose implementations are interchangeable or can be combined. Take a look at the search results for Microsoft.Extensions.*.Abstractions on NuGet.org.
Learn to model the project architecture of your solution
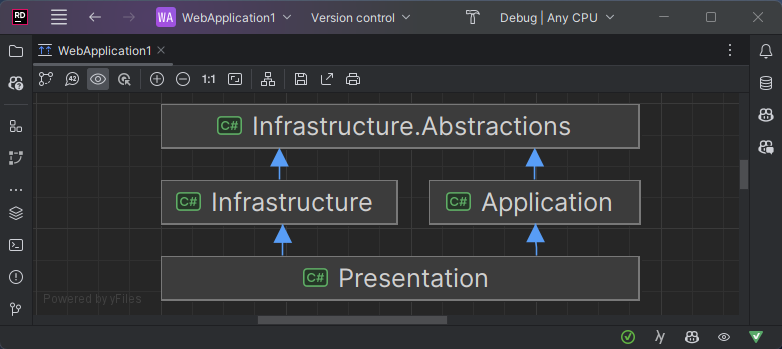
To better understand how to apply inversion of control to the architecture of a .NET solution, it’s important to understand how to model a solution and identify dependencies between projects.
In Rider, it is possible to view a dependency diagram between the projects of a solution. It is also possible to do the same with Visual Studio.
Conclusion
In this second and final part concerning the optimization of .NET solution compilation, we saw how inversion of control can be applied to the architecture of a .NET solution to reduce compilation time. In our example, we reduced the compilation time from 12 seconds to 7 seconds. In a real solution, the savings can be several minutes. Moreover, the solution architecture is more robust and easier to maintain in the long run.
I hope this article has been helpful to you. Feel free to react in the comments or contact me on Twitter @asimmon971.